 無念Nameとしあき26/05/06(水)21:33:52No.1405966594+
03:31頃消えます
無念Nameとしあき26/05/06(水)21:33:52No.1405966594+
03:31頃消えます
Mac miniでAIエージェントを立ち上げるのがトレンド
時代の最先端に立とう!
| … | 1無念Nameとしあき26/05/06(水)21:36:41No.1405967367+積んでるエロゲーを代わりにプレイしてもらって |
| … | 2無念Nameとしあき26/05/06(水)21:42:14No.1405968863+ストレージ512Gで足りる? |
| … | 3無念Nameとしあき26/05/06(水)21:44:37No.1405969510+m1でも大丈夫? |
| … | 4無念Nameとしあき26/05/06(水)21:54:53No.1405972284そうだねx1 1778072093627.webp-(80494 B) 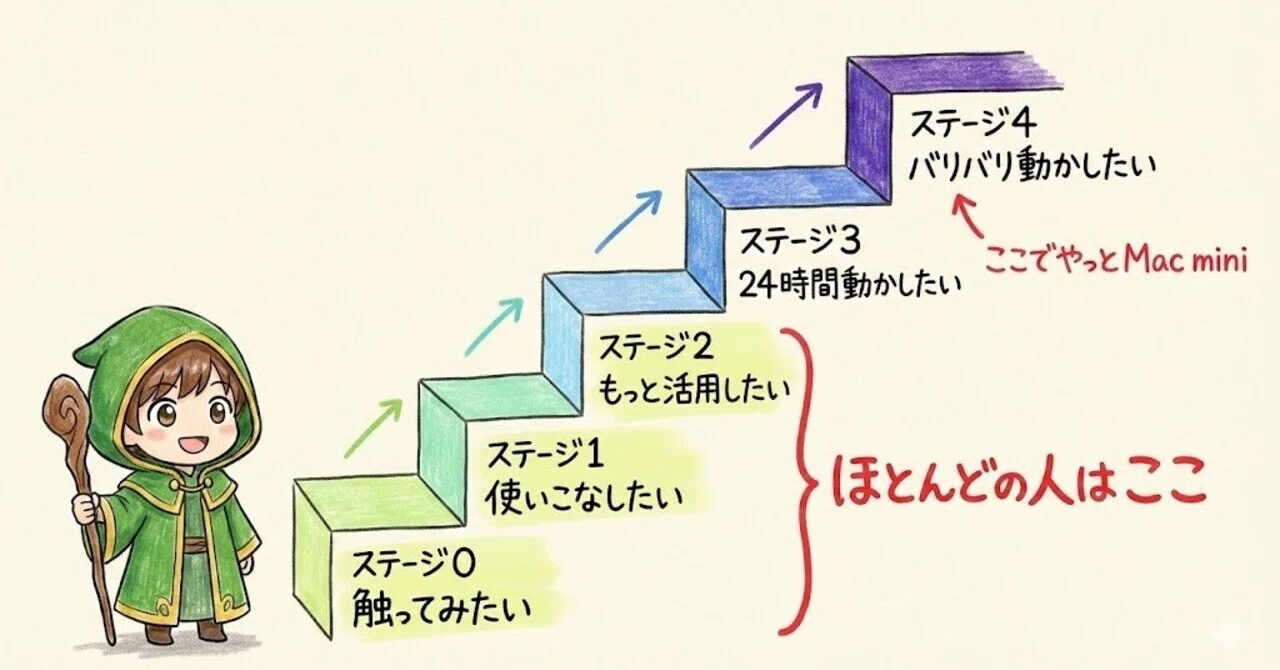 キタ━━━(゚∀゚)━━━!! |
| … | 5無念Nameとしあき26/05/06(水)21:55:17No.1405972404+ 1778072117735.webp-(63126 B) 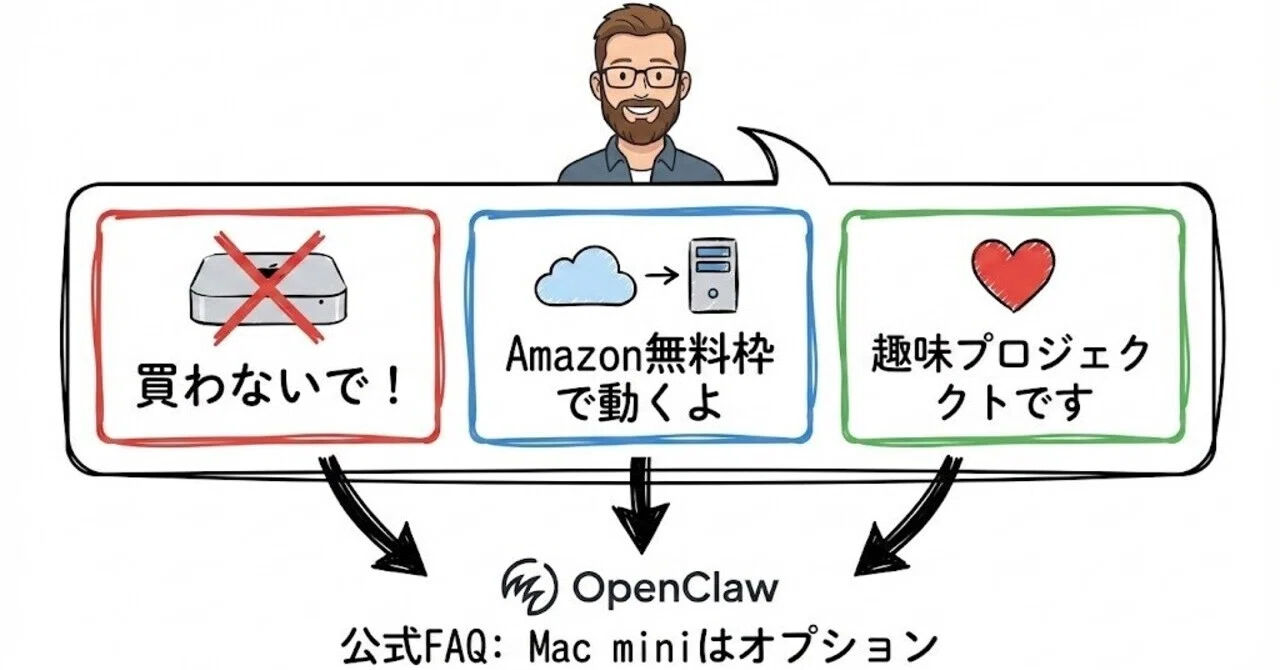 キタ━━━(゚∀゚)━━━!! |
| … | 6無念Nameとしあき26/05/06(水)21:57:20No.1405972950+フルサイズ動くのは魅力的だけど15トークン/sとかいわれておっそ… |
| … | 7無念Nameとしあき26/05/06(水)22:02:44No.1405974367+ユニファイドメモリの上限64GBでしょミドルクラスのLLMしか動かないんじゃ?RTX5090の32GBよりは上だけどさ |
| … | 8無念Nameとしあき26/05/06(水)22:06:02No.1405975243+地味にたけー |
| … | 9無念Nameとしあき26/05/06(水)22:11:54No.1405976787+>ストレージ512Gで足りる? |
| … | 10無念Nameとしあき26/05/06(水)22:16:12No.1405977929+ 1778073372060.webp-(55716 B)  こいつくらいのことできる? |
| … | 11無念Nameとしあき26/05/06(水)22:36:22No.1405982587+次のstrix haloがオンチップで最大192GB積むらしい |
| … | 12無念Nameとしあき26/05/06(水)23:13:31No.1405990847+CUDAネイティブじゃないとな… |
| … | 13無念Nameとしあき26/05/06(水)23:26:14No.1405993765+ 1778077574656.jpg-(97358 B) 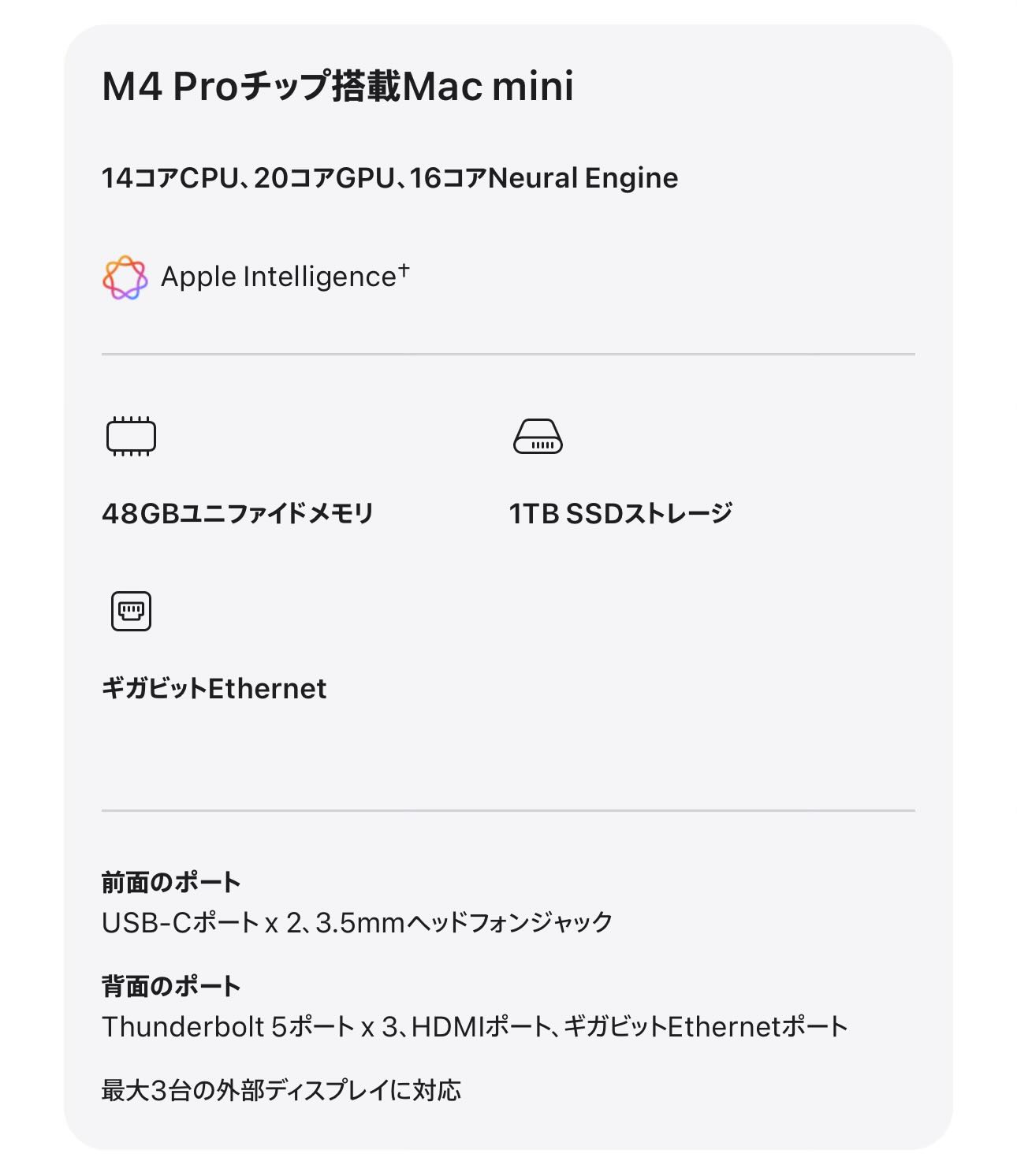 これは意外と安いか? |
| … | 14無念Nameとしあき26/05/06(水)23:27:17No.1405993980そうだねx1俺の初代のPowerPCのMac miniでも出来る? |
| … | 15無念Nameとしあき26/05/06(水)23:29:13No.1405994370+>俺の初代のPowerPCのMac miniでも出来る? |
| … | 16無念Nameとしあき26/05/06(水)23:30:58No.1405994687+ 1778077858344.jpg-(111029 B) 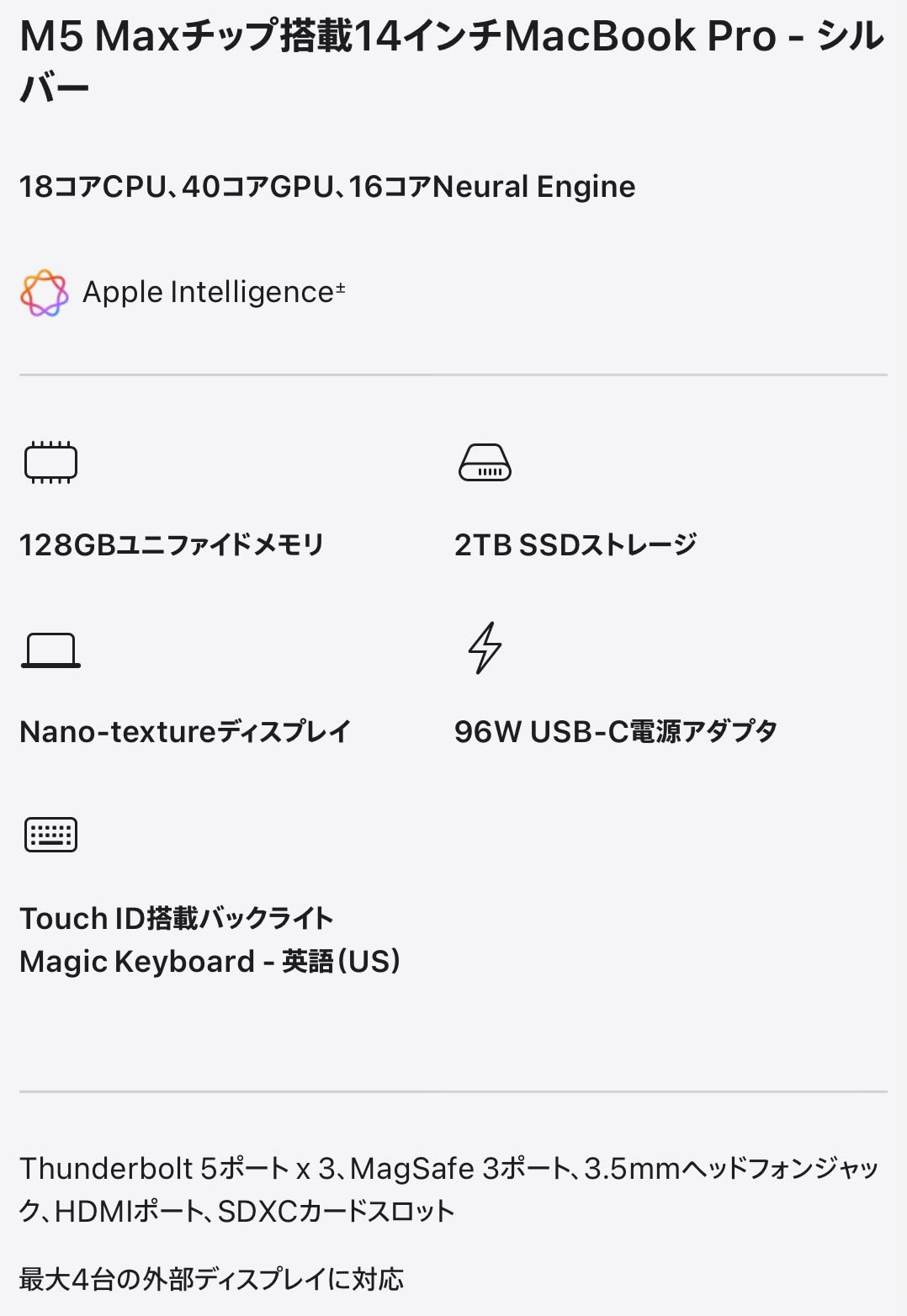 これ買えば俺も一流のAIオペレーターなってすごいことできる? |
| … | 17無念Nameとしあき26/05/06(水)23:38:50No.1405996310+ 1778078330360.jpg-(98547 B)  >俺の初代のPowerPCのMac miniでも出来る? |
| … | 18無念Nameとしあき26/05/06(水)23:46:19No.1405997736+性能的にはオンラインサービスLLMのモデルサイズが2桁以上違うのでローカルLLMにこだわる意味はない |
| … | 19無念Nameとしあき26/05/06(水)23:54:02No.1405999158+あー、gemma4-31BがM5@32GBで6t/sしか出ないのか |
| … | 20無念Nameとしあき26/05/06(水)23:56:30No.1405999602+>こいつくらいのことできる? |
| … | 21無念Nameとしあき26/05/06(水)23:56:46No.1405999664+Googleが発表してたメモリ節約する技術の実装はまだ? |
| … | 22無念Nameとしあき26/05/06(水)23:58:40No.1406000022+暗号化ZIPファイルの解読してもらおう |
| … | 23無念Nameとしあき26/05/07(木)00:00:16No.1406000305+ 1778079616430.png-(204390 B) 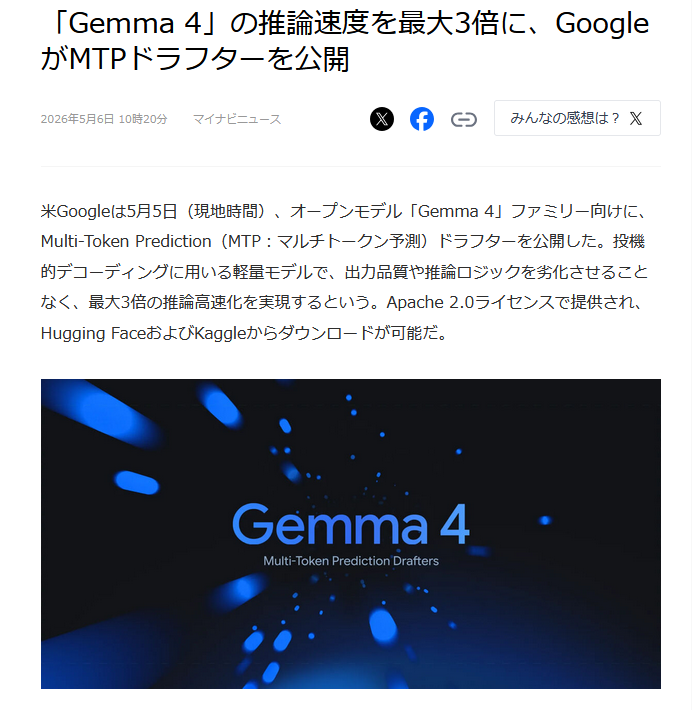 >あー、gemma4-31BがM5@32GBで6t/sしか出ないのか |
| … | 24無念Nameとしあき26/05/07(木)00:01:35No.1406000585+TurboQuantは用途が違う 減るのはKVキャッシュ(context length)で |
| … | 25無念Nameとしあき26/05/07(木)00:03:21No.1406000926+>最大3倍速になるってよ |
| … | 26無念Nameとしあき26/05/07(木)00:23:37No.1406004497+>あー、gemma4-31BがM5@32GBで6t/sしか出ないのか |
| … | 27無念Nameとしあき26/05/07(木)00:40:43No.1406006877+その値段で素直にゲフォ機組んだほうが良さそう |
| … | 28無念Nameとしあき26/05/07(木)00:41:20No.1406006962+>CUDAネイティブじゃないとな… |
| … | 29無念Nameとしあき26/05/07(木)00:42:24No.1406007100+LLMはどっちかというとデカいモデル置けるデカくて速いメモリが大事だからな |
| … | 30無念Nameとしあき26/05/07(木)00:44:33No.1406007360+>性能的にはオンラインサービスLLMのモデルサイズが2桁以上違うのでローカルLLMにこだわる意味はない |
| … | 31無念Nameとしあき26/05/07(木)00:48:23No.1406007814+>LLMはどっちかというとデカいモデル置けるデカくて速いメモリが大事だからな |
| … | 32無念Nameとしあき26/05/07(木)00:49:55No.1406008010+Apple Mシリーズの初期はメモリ帯域より処理能力がボトルネックになってたような |
| … | 33無念Nameとしあき26/05/07(木)00:51:28No.1406008197+>その値段で素直にゲフォ機組んだほうが良さそう |
| … | 34無念Nameとしあき26/05/07(木)00:52:37No.1406008329+それ言い出すとローカルでLLM組む意味なくない? |
| … | 35無念Nameとしあき26/05/07(木)00:53:20No.1406008423+>>その値段で素直にゲフォ機組んだほうが良さそう |
| … | 36無念Nameとしあき26/05/07(木)00:54:09No.1406008519+AIコピペスレかと思った |
| … | 37無念Nameとしあき26/05/07(木)00:54:13No.1406008533+最近のはVRAMが限られていてもオフロードで案外動くんだよな |
| … | 38無念Nameとしあき26/05/07(木)00:54:21No.1406008547+>それ言い出すとローカルでLLM組む意味なくない? |
| … | 39無念Nameとしあき26/05/07(木)00:55:20No.1406008666+去年ならユニファイドメモリ512GBのMac studioが150万だったんだよな… |
| … | 40無念Nameとしあき26/05/07(木)00:55:39No.1406008709+AI研究って圧倒的資産蓄積のあるCUDA使えないとダメかと思ってた |
| … | 41無念Nameとしあき26/05/07(木)00:56:02No.1406008752そうだねx1>去年ならユニファイドメモリ512GBのMac studioが150万だったんだよな… |
| … | 42無念Nameとしあき26/05/07(木)00:56:43No.1406008834そうだねx1>去年ならユニファイドメモリ512GBのMac studioが150万だったんだよな… |
| … | 43無念Nameとしあき26/05/07(木)00:57:27No.1406008936+>AI研究って圧倒的資産蓄積のあるCUDA使えないとダメかと思ってた |
| … | 44無念Nameとしあき26/05/07(木)00:59:23No.1406009164+ローカルLLMって企業ユースってことになると思うけど |
| … | 45無念Nameとしあき26/05/07(木)00:59:47No.1406009208+AI研究用って言ってもよ |
| … | 46無念Nameとしあき26/05/07(木)01:01:07No.1406009342そうだねx1>ローカルLLMって企業ユースってことになると思うけど |
| … | 47無念Nameとしあき26/05/07(木)01:02:56No.1406009554+>OpenAIやAnthropicの開発ツールがMac最優先で出る程度には少ないな |
| … | 48無念Nameとしあき26/05/07(木)01:07:07No.1406010048+ビジネスだとAppleに信用無いから |
| … | 49無念Nameとしあき26/05/07(木)01:08:45No.1406010229+AI驚き屋のプラットフォームだからな |
| … | 50無念Nameとしあき26/05/07(木)01:17:18No.1406011165+QWEN3.5-35Bがコーディングエージェントとしてそれなりにまともに使えると聞いて気にはなってる |
| … | 51無念Nameとしあき26/05/07(木)01:21:47No.1406011597+Mac mini M4 pro 128GBメモリを買いたいのに買えない |
| … | 52無念Nameとしあき26/05/07(木)01:22:30No.1406011679+Qwen3.6 27Bの方がいいよ |
| … | 53無念Nameとしあき26/05/07(木)01:24:21No.1406011863+会話の感触はGemmaの方がいいけど基本性能はQwenの方が高い気がする |
| … | 54無念Nameとしあき26/05/07(木)01:27:53No.1406012203+GeminiのサブエージェントとしてはGemma4もいい感じ |